Hadoop is a software framework for creating a cluster of servers to handle huge amounts of data which in turn leads it to be called Big Data processing.
BigData should be in 3 “V”s, Volume , Velocity and Variety.
Volume : The amount of dat generated
Velocity : Speed of your data analysing
Variety : Data types.
BigData can be used to build a better product, services and also better predict the future for your business. Lots of companies like Facebook, Twiter, LinkedIn, ebay, google, etc., generating Yottabytes [YB] of data.
A Hadoop architecture can handle multiple Data data types including
- Structured Data
- Unstructured Data
- Semi- Structured Data
A large percentage of data in the industry are being unstructured data (like texts , images , videos , etc.) here comes Hadoop to processing these unstructured data for further analysis.
Apache Hadoop framework consists of the following modules:
- Hadoop Common
- Hadoop Distributed File System – HDFS
- Hadoop YARN – Resource management tool
- Hadoop MapReduce
Apache Hadoop using lots of data access technologies like Apache HBase , Apache Hive, Apache Pig, etc., For interacting with your data.
History of Hadoop:
In early 1999 we have used our search engine as AltaVista ,Go.com, Netscape etc , but after year 2000 the majority of users went to Google.com. And they became the most popular for people all over the world for finding web pages of their interests. Also, they have developed the idea of selling search terms. Everyone thinking for the secret behind their technology. Google finally releases some white paper regarding their technologies.
Interesting fact behind Hadoop name:
Daug Cutting’s son has a yellow colored toy elephant and the name of the toy was Hadoop. So he named this new software as Hadoop and it is ease to pronounce as well.
Revolutionary recap:
2003 :- Google introduces a project Nutch to handle billions of searches and Indexing
2003 :- Google releases white paper regarding GFS [ Google File System]
2004 :- Google releases white paper regarding MapReduce
2006 :- Yahoo created Hadoop based Filesystem [HDFS] and MapReduce.
2007 :- Yahoo used their technology on a 1000 node cluster.
2008 :- Apache taken Hadoop and licensed as Open-Source software.
2011 :- Hadoop release version 1.0
2013 :- Hadoop release version 2.0
2015 :- Hadoop release version 2.7
So the real brain behind Hadoop is Google’s GFS and MapReduce, and they give the first light to this great project.
At first yahoo faced some issue with implementing Hadoop on a 1000 node cluster system. In 2008 Apache successfully implemented Hadoop on a 4000 node cluster system.
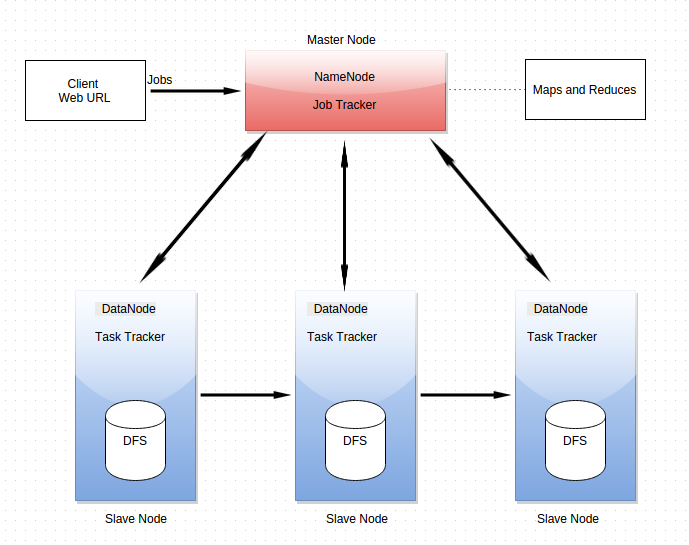
Basic Architectural Diagram of Hadoop:
![]()